
Head of DevOps at fenzidogsportsacademy.com monitoring systems during enrollment!
Watching payments, logs and customer tickets and CPU load all in a day’s work!
Head of DevOps at fenzidogsportsacademy.com monitoring systems during enrollment!
Watching payments, logs and customer tickets and CPU load all in a day’s work!
Given that I work in the gaming industry, I am always fascinated with what people will do with Lua.
The Terra project struck me as an interesting investigation into building a better low-level counterpart to Lua that is not C.
The key claim to fame for Terra is that it is a dynamic language that has near native performance because it is less dynamic than Lua.
The idea behind Terra and Lua is to use Lua as a scripting language for rapid prototyping and Terra for optimized components without having to deal with the messiness of dropping into C. What makes this particular system intriguing is that the Terra functions are in the same lexical environment as the Lua functions which means they inter-operate seamlessly while having the Terra functions execute outside of the Lua VM… as per their abstract:
High-performance computing applications, such as auto-tuners and domain-specific languages, rely on generative programming techniques to achieve high performance and portability. However, these systems are often implemented in multiple disparate languages and perform code generation in a separate process from program execution, making certain optimizations difficult to engineer. We leverage a popular scripting language, Lua, to stage the execution of a novel low-level language, Terra. Users can implement optimizations in the high-level language, and use built-in constructs to generate and execute high-performance Terra code. To simplify meta-programming, Lua and Terra share the same lexical environment, but, to ensure performance, Terra code can execute independently of Lua’s runtime. We evaluate our design by reimplementing existing multi-language systems entirely in Terra. Our Terra-based auto-tuner for BLAS routines performs within 20% of ATLAS, and our DSL for stencil computations runs 2.3x faster than hand-written C.
I don’t have enough experience with Lua to offer any insight as to whether this is a good idea… but it bounced along the internet superhighway so I’ll try to take a look.
Reading the paper, I realized there is a lot more there in terms of the sophistication and science of the challenge of integrating these two different languages. Okay… I’ll have to read and noodle.
Programmers everywhere still squirm when they remember this scene from Hackers

It was Hollywood’s pathetic attempt to make programming look cool … And it was groan inducing scene.
Over the years my wife and I have taken a certain perverse pleasure in inspecting what code is used on-screen. And over time we have found that the code has gone from nonsense, to recognizable constructs, to valid but irrelevant programs.
The Holy Grail was software on-screen that was correct and relevant.
We have found our Grail. In Revolution, a TV show we like, a character approaches a biometric terminal. On the terminal is code.
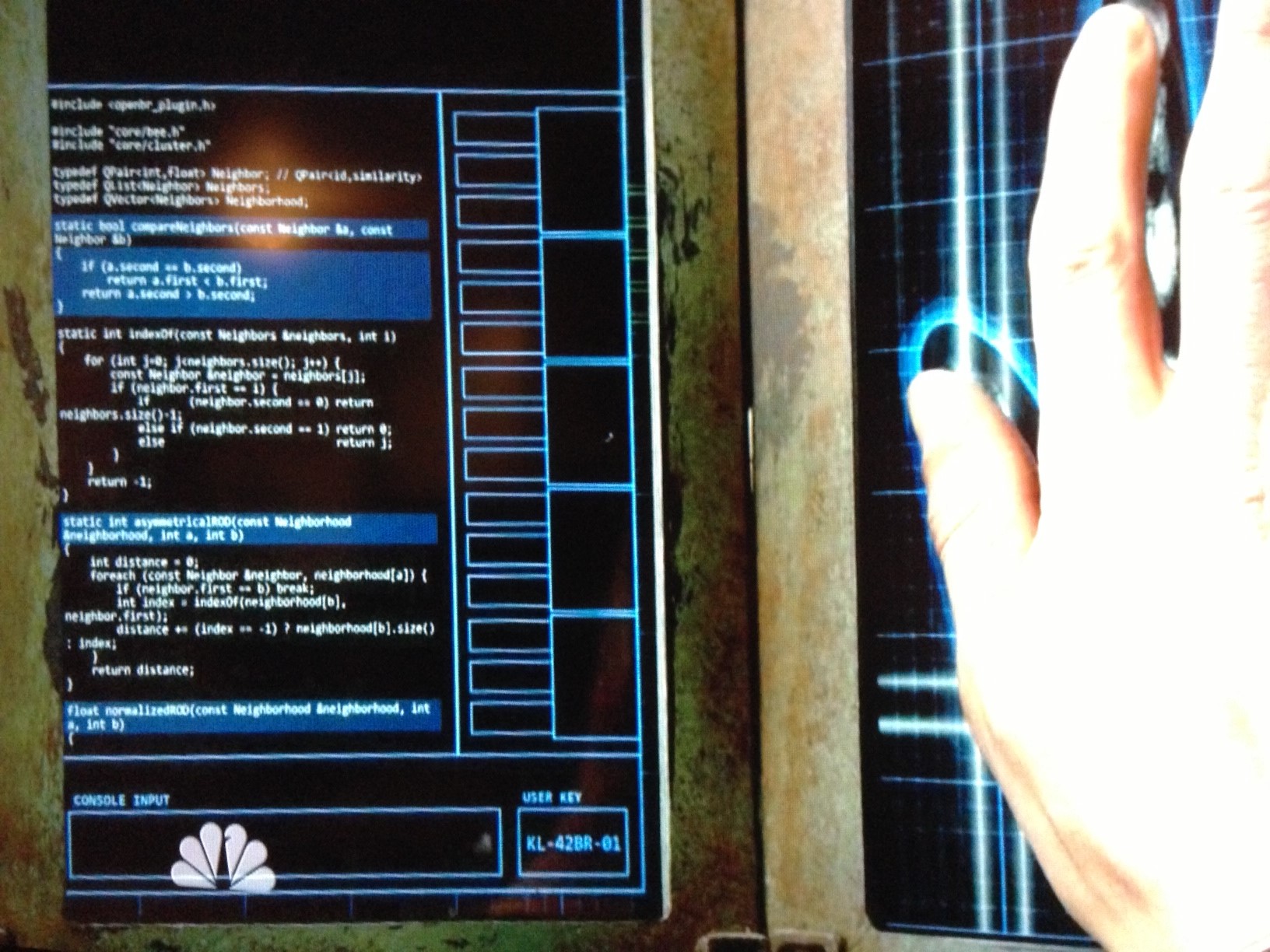
And the code is correct and relevant code. It’s software using code from the open biometrics initiative … And just in case the apocalypse does happen you and need some code … here’s the github repo.
My only thought was in the apocalypse, we will have no shortage of C++ programmers because C++, C++ is the correct answer.
For the purposes of this discussion I will use the term application and system interchangeably to describe a piece of software with more than 300k lines of code and with more than 5 developers.
Dynamic programming languages allow you to make the Faustian bargain of ease of prototyping at the expense of maintainability. They let you prototype your system quickly without having to think too deeply about the core abstractions. In an application space where the core abstractions are hard to determine because the business is so new, this is a good thing. No point in thinking through the abstractions when you are building something radically new.
However, at some point, software becomes more permanent as the business it supports becomes more permanent. At that point in time abstractions become necessary to get engineering leverage. And then the Devil turns on you. Because the lack of abstractions early on make it hard to define them later. Worse, because of the dynamic nature of the language, it becomes hard to impose rules on the abstractions on the programmers. And as the team scales it becomes increasingly harder.
Over time you get a large piece of software for which reasoning about becomes increasingly more difficult.
And then you try and make the dynamic language more structured with more well defined abstractions and rules that the compiler and language and tools do nothing to help you with.
So the choice is always yours, pick a dynamic language and have no support when your business scales, or pick a structured language and struggled with the type-safety.
At the end of the day, you either believe types and abstractions make for productivity or you don’t. If you do, then you agree with me. If you don’t then you don’t. But 30+ years of programming language design has taught us that types do matter.
Nude pics in phone lost at McDonald’s get online
FAYETTEVILLE, Ark. – Here’s some food for thought: If you have nude photos of your wife on your cell phone, hang onto it.
Phillip Sherman of Arkansas learned that lesson after he left his phone behind at a McDonald’s restaurant and the photos ended up online. Now he and his wife, Tina, are suing the McDonald’s Corp., the franchise owner and the store manager.
The suit was filed Friday and seeks a jury trial and $3 million in damages for suffering, embarrassment and the cost of having to move to a new home.
The suit says that Phillip Sherman left the phone the Fayetteville store in July and that employees promised to secure it until he returned.
Manager Aaron Brummley declined to comment, and other company officials didn’t return messages.
D’oh.
With 8 GB of storage, a reasonably good camera, and a desire to photograph everything for posterity, this is going to be happening a lot more frequently than we would like.
I believe being able to remotely wipe a phone of all contents is going to be a key feature of cell phone’s going forward.
And sooner rather than later, folks are going to learn the value of encryption and strong passwords.
I wonder if we’ll see biometrics make it into phones?
When I started my career many moons ago at SGI, I discovered that there was a set of really smart folks who viewed software development not as an engineering discipline but more akin to developing mathematics, or writing poetry.
There is a certain intellectual appeal to such a notion. If software, is indeed poetry, or beautiful, then that means that computer scientists are not merely engineers building devices using well defined rules, but we are artists creating something that has enduring value.
More to the point, it means that the software itself has intrinsic value beyond that of the particular product that it ships with.
So as software craftsmen, our job is not to merely satisfy the immediate customer requirements but to develop the perfect set of software that had enduring value that also happens to meet the customer requirements.
For some reason, this never really worked for me. At some point, software is good enough, not perfect, and we need to move on to the next problem.
What appeals to me about software development is the part where the end product is used by someone to solve a real problem. I want to engineer, which means to make tradeoffs, a solution that people want to buy.
I am not interested in understanding what can be developed within the constraints of computability.
And in many ways, I am beginning to think that the software as mathematics crowd tends to have a dim view of software as engineering, because they are not engineers and don’t see beauty in engineering.
Which puts me in a different camp from the software is beautiful camp. I am in the camp that views the pursuit of software beauty as an end unto itself, a waste of time.
Now lets be clear, it’s not that I think software can not be perfect or beautiful, I do. Nor does it mean that I think that there is no distinction between beautiful software and butt ugly software, I do. And thanks to the discipline that those great engineers instilled in me at SGI, I think I was actually able to approach beautiful code. It’s just unclear to me how the pursuit of this perfection got me any closer to my revenue goals.
I find beauty in products that exceed customer expectations, that are cheaper to develop than was expected and are easy to evolve at a low cost. I view the underlying software as a means to that end, but not the end in and of itself. And yes, I do understand that sometimes it’s elegant beautiful software that makes that possible.
I think the art of engineering is to understand where to invest your time and energy to get meaningful product differentiation and where to just live with problems. And I think it’s an art, because you never really know if you pulled it off until someone, somewhere opens their wallet and forks some money over to you because they want your product: not your software, your product.
Which brings me to the title of my blog. I think that there is a tension in computer science between engineering and mathematics. And I think that there is a a class of computer scientists who think of themselves as mathematicians building fundamental abstractions. And I also think that there is another class of computer scientists who think of themselves as engineers who try and deliver differentiated products that exceed customer demands with imperfect software.
And I think that between the two camps there can be no reconciliation.
When I started my career as a software engineer at SGI in 1996, I had the privilege of working with a great engineer.
This engineer and I had very different perspectives on software. I viewed software as a means to an end. As a vehicle to deliver the features that the were asked of me. That the perfection of the software was immaterial, what was material was how fast you could deliver those features. In fact, sloppy, disorganized, poorly structured code was okay as long as it worked. What was material was the function not the form.
He, on the other hand, felt that software was like poetry. That it had its own intrinsic beauty and that its beauty was an end in and of itself.
That’s not to say that he did not care about the outcome and the product. He was always passionate about delivering value to customers. He just felt that the elegant, solution was always better than the quick solution.
Being young, and he being great, I was convinced that elegance was worth the price in time and effort.
I’m not sure I still agree with him.
My career is littered with software systems that are no longer in production. SGI’s kernel was EOL’ed last year. NetCache was sold off to Bluecoat. Most of the code I wrote for DFM has been re-written as more and different requirements came into existence.
And he would say that is natural and normal and a reflection of the natural process of things.
And I wonder.
Was it really worthwhile to strive to create the perfect solution given the market pressures? Would I have been better off to just get the job done in the most expedient way possible?
Ultimately, I think the answer boils down to an engineering tradeoff. The perfect solution makes sense if you understand the requirements and the requirements are stable. But if the requirements change, then your attempt to create perfection has to be balanced against expediency and need.
Although I can appreciate a beautiful piece of code, I somehow am more inspired by a system that is easily adapted. A systems whose core abstractions although imprecise are in the right general area and allow for substantial independent directions of innovation.
Let me try this differently.
I think it’s far more valuable to know what the core set of abstractions should be and their general properties than to specify them completely. Instead of trying to perfect them in isolation, one should expose them to the real world and then learn. And if the abstractions were correct, over time they will get precisely defined and perhaps at some point become perfect, as they no longer evolve.
But I suspect that I will have long since moved onto the next set of imperfect abstractions.
And in retrospect, that engineer always remarked that it’s much easier to replace an elegant easily understood solution than a complex, baroque, over or under-engineered hack that was expedient.
One of the persistent worries I have is whether a particular technology I am in love with is really a boondoggle. In other words, the technology solves a hard problem in an interesting way that is useful because of some abnormal discontinuity computer system performance, but in reality is of transitory interest so spending much time and energy on the problem is of limited value.
Having said that, I thought to myself, well what is a computer science boondoggle exactly?
So I came up with the following pre-requisites of a boondoggle:
The field goes on boondoggle when someone determines that the barrier to using the compute resource is the application modification and so tries to come up with ways to transparently take advantage of said resource. In effect, the allure of this free compute resource, and the challenge of making it usable drags people down a rabbit hole of trying to make it easy to just transparently use this new compute resource!
The boondoggle ends when the compute resources that require no application modification eventually catch up eliminating the need to modify applications or use special libraries to get superior performance.
As an example, consider Software Distributed Shared Memory (SDSM). SDSM began life when people observed that in any engineering office there were these idle workstations that could be connected together to create a cheap supercomputer. People then observed, that to take advantage of said resource applications would have to be modified. So some applications were modified and performance gains were real. And it could have all ended there.
The SDSM boondoggle took hold, when some bright folks realized that modifying every application was going to take too much time. So they decided to invent this rather elegant way to allow applications to run, unmodified, on these networks of workstations. Of course, the problem was that applications assumed uniform memory access and SDSM provided non-uniform memory access, whose non-uniformity was measured in the 10s of milliseconds. Because of the latency issues and the non-uniform memory access, these unmodified applications performed poorly. It could have all ended right there, but the allure of this transparent way to take advantage of the performance of these idle workstations was so tantalizing that folks spent a significant amount of energy trying to make it work.
They failed.
What did happen was that computers got bigger and faster and cheaper making the performance gains less and less interesting given the amount of effort required to make them work using SDSM.
So SDSM was trying to exploit a discontinuity in computing resources (the relative costs of a collection of workstations versus a supercomputer), was trying to do it in an interesting way, but in reality was not of long term value because of the hardware compute trends that were in place at the time.
It’s happened. My Apple friends, you know the ones who run around proclaiming the Mac’s greatness, have gotten their hands on iPhones. Now I will be subjected to claims about how great the iPhone is and how it changes everything in the cell phone market. Already they are asking whether, Nokia, the global leader with 400 million phones sold per year and approximately 50 000 employees devoted to exactly one market is doomed, doomed I tell you.
Let us, for a moment, exit the Steve Job’s reality distortion field. So I’ll make two seemingly contradictory statements:
Let me start with (1).
Apple has consistently occupied a niche in the broader general personal compute market. A market I define to include all devices that people use to browse the web, message, entertain themsevles and generate content with. If you exclude the biggest segment, the cell phone, Apple’s global share of the PC market is an almost irrelevant 5%. The problem for Apple is that the 5% Apple owns is absolutely irrelevant to the emerging personal compute platform that is the cell phone. In other words, regardless of whether Apple owned 10 or 15% of the laptop market without some kind of cell phone strategy the long term prospects of the company were questionable. The thesis for this argument is that as more and more users migrate to cell phones to do most of their laptop activities, the value of the laptop declines and the value of the cell phone as their dominant personal compute platform increases. In other words, over time, the cell phone becomes the laptop, the laptop becomes the desktop, and the desktop becomes the mainframe. Why this is important to Apple, is that Apple’s market tends to self select among people who are willing to adopt newer and more exotic technologies. There was always the possibility that the right phone may affect Apple faster than the broader Microsoft market.
Furthermore, the reality is that unlike Microsoft, who after 6 years of trying finally has finally produced a credible cell phone OS that actually runs on a non-trivial amount of cell phones Apple had zero presence in the market. Vista and Mobile Windows are fairly well integrated and that the integration creates the possibility that the Mobile Windows may drive Windows OS sales over time. This could, in theory, impact Apple’s long term (tiny) position in the computer market.
Apple had two strategies open to it. One was to try and get cell phone manufacturers to adopt the Mac OS or Apple applications preserving some kind of presence in the cell phone market. The second was to build their own custom designed cell phones. Proving, again, that Apple is a hardware and not software company, the strategy they chose to adopt is to build their own phone with their own OS. In effect, Apple decided that Apple needed to build their own device so as to provide a home for their fans so as to preserve Apple’s overall share of the personal compute market.
In fact, the iPhone’s success is critical to Apple. If the iPhone flops, this may create an oppening for some of those Apple users to migrate to other computer platforms. The reason may be better integration with their dominant compute platform, namely the cell phone. Thankfully, for Apple, the early news is that the ancient hardware platform they built has been a smashing success with their fans, thanks to the rather clever software interface they built. So kudos to Apple!
Having just congratulated Apple on their first phone, I am worried that the first cell phone they produced was already ancient in terms of hardware technology. The cell phone market is not the mature PC market. The cell phone is a rapidly evolving hardware platform. There is an open question as to whether Apple can simultaneously sustain the level of innovation in both the PC and cell phone market necessary to compete over the long haul. An iPhone that is always two years behind the rest of cell phone market becomes less interesting over time.
Now let me address point (2):
Even if the iPhone succeeds it is irrelevant to the broader cell phone market and will barely affect the broader cell phone market.
The most irritating aspect of the Apple fan is his belief that the iPhone will somehow change the dynamics of cell phone market or perhaps even disrupt the dominant player in the cell phone market, Nokia. The central thesis of the argument is the following:
Before I even point out why I think this argument is deeply flawed, let me observe that the iPhone is irrelevant to the broader cell phone market.
The total cell phone market is approximately 1 000 000 000 cell phones (http://www.ipsnews.net/news.asp?idnews=36161) per year. If the iPhone sells 5 million per year that’s 0.5% of the global market. As a point of comparison, Nokia sold 106 million phones in the quarter ending Jan 1st 2007 (http://www.infoworld.com/article/07/01/25/HNnokiasalesup_1.html)
Heck even in the United States there are approximately 120 million subscribers between verizon and att. Assuming 1 cell phone per subscriber, if the iPhone sells 10 million units it will have hit ~8% of the verizon/att market and less than 4% of the total US market.
Practically speaking the iPhone may eventually own a tiny market of the global market, but is utterly irrelevant in the places where the growth in phones is most dramatic (the emerging markets of China, India and Africa) because of the cost and form factor of the device.
The most optimistic scenario for the iPhone for it’s impact therefore, is the following:
I think in the most optimistic scenario,the iPhone is to the general mobile cell phone market what the Mac is to the PC: pushing a few trends faster but generally irrelevant.
Of course, anyone who believes in disruptive technology will gladly point out that the dominant players are never weaker than when they appear strongest.
So is the iPhone like the iPod, disruptive to the rest of the cell phone market?
I think the answer is no. The iPod was disruptive to the personal media market because it was the first device that had enough capacity to carry most of your music as well as an elegant form factor. The iPod was, therefore, able to take advantage of the transition of media to digital form. The reason no one else was able to respond was that the players in the market at the time were either too small to compete with Apple or (cell phone manufacturers and Microsoft) completely missed the boat.
The iPhone has a pretty UI on top of a marginal hardware platform. Apple has not invented the first usable cell phone. Apple may have invented the first usable cell phone based web browser. However, the problem is that the cell phone vendors are not some puny players that are incapable of reacting and Apple’s global share is too small to make their current advantage meaningful. The most reasonable claim is that Apple’s disruptiveness is tied to the fact that they do software and they understand industrial design. The problem is that cell phone vendors understand industrial design (Motorolla RAZR) and increasingly understand the value of software (possibly because of Microsoft). The major cell phone manufacturers are aware of the importance of the software platform and have been aggressively investing and re-organizing to become software players. If you combine their ability to innovate in hardware, their manufacturing capacity, their global reach and their new found focus to create software the most likely outcome is what I said earlier:
I think in the most optimistic scenario,the iPhone is to the general mobile cell phone market what the Mac is to the PC: pushing a few trends faster but generally irrelevant.
I just don’t see the cell phone vendors falling asleep and giving Apple the time necessary to build the capacity necessary to compete with them. Of course, I could be wrong, but it seems extraordinarily unlikely.
I still believe the largest long term threat to the cell phone manufacturers and in particular Nokia is Windows Mobile because of the increasing integration between the cell phone and the laptop. Having said that, the laptop may become irrelevant over time, making that integration a niche part of the overall personal compute market.
In short, bravo to Apple for introducing a good phone. But unlike Steve, I believe this changes nothing.
In an earlier post I talked about the nature of NetApp’s hard problems, and I claimed that there were three factors:
In this post I’ll try and give some detail about 1 and 2.
For NetApp the basic technologies that have been driving our innovation, which is the fancy word for saying the set of hard problems that we’ve solved, has been and continues to be networks, storage media and commodity computing.
Back in the day when NetApp was founded the traditional computing system consisted of a CPU, RAM, some input and output devices and some form of stable storage. This form of computing is still how desktop PC’s and laptops are built. However, in the data center traditional computing systems have changed dramatically.
As an aside, data center is a terms that is used to describe the set of computers that are not used for personal computing but are a shared computing resource across a company or institution. Normally we associate the term data center with the enterprise, but really any company that has a shared computing resource (such as email or file serving or print serving) has a data center and this discussion applies to them as well as to the Fortune 500.
What caused that change was networking speeds, and commodity computing.
The traditional computer system made a lot of sense because of the ratios of performance between the components. Every normal application assumes that RAM has a fast uniform access and that storage has a predictable slow access. The performance of the application is a function of the speed of the CPU and the speed with which you can get data to and from RAM and to and from stable storage. Now it turns out that RAM and stable storage are much slower than CPU’s. Caching and clever algorithms are used to improve the performance of applications by trying to hide the latency of both RAM and stable storage. For storage, I’ll just state those algorithms were in the VM, file system, volume manager and RAID subsystem.
Now it turns out that the algorithms that were used to improve disk performance were executing on the same CPU that the application itself was running. Worse, the storage sub-system was competing with the application for the far more scarce resource of memory bandwidth. As the application demands for more CPU and memory bandwidth increased, the CPU cycles that were being consumed by the storage system were critically looked at and reasonable people started to ask whether the storage system really did require so many CPU cycles. In fact, some folks actually believed that the existence of general purpose storage sub-systems was the source of the performance problem. They therefore argued for eliminating all of those clever file systems and replacing them with custom per application solutions. The problem with that approach was that no one wanted to write their own file system, volume manager and RAID subsystem.
In software computer science every problem can be solved with a layer of indirection. In hardware computer science, every performance problem with a dedicated computing element.
The computer industry (and the founders of NetApp in particular) observed that there was a layer of indirection in UNIX between the storage sub-system and the rest of the computing system, and that was the VFS layer and NFS client. They also observed that because Ethernet network speed was increasing the storage subsystem could be moved onto it’s own dedicated computing element. In effect, the speed of the network was not an issue when it came to the predictability or slowness of the storage. Or more precisely by moving the storage sub-system out of the main computer they could use more computing and memory resources to compensate for any increased latency caused by the stable storage no longer being directly attached to the local shared bus. In fact in the 1990’s NetApp used to remark that our storage systems were faster than local disks. They further observed that the trends of commodity CPUs allowed them to build their dedicated computing element out of commodity parts this made it cost effective to build such a computing element. Designing your own ASIC is absurdly expensive.
Now it also turned out that putting the data on the network had some additional benefits beyond just performance. But it was those networking and CPU and disk drive technology trends that enabled the independence of storage subsystems.
It’s almost too obvious to point out, but you can not just attach an Ethernet cable to CPU a to disk drive and have networked storage. In fact, the challenge we have at NetApp is how to combine those components into a product that adds value. In effect the source of all of our hard problems is how to write clever algorithms that exploit the attributes and hide the limitations of disks to add value to applications that require stable storage within a particular cost structure (CPU and RAM and Disk).
Which gets me to item 2, trade-offs, of my list. If you have an infinite budget, you could construct a stable storage system that had enough memory to cache your entire dataset in battery backed RAM. You could imagine that periodically some of the data would be flushed to disk. Such a storage subsystem would be fairly simple to construct but would be ridiculously expensive. In effect, insufficient customers would pay for it.
In effect, customers want a certain amount of performance that fits into their budget. The trick is how to deliver that performance. And the performance it turns out is not just about how fast you perform read and write operations, but in fact encompasses all of the tasks you need to perform with stable storage. And this where things get messy.
Performance for a storage sub-system is of course about how fast you can get at the data, but also how fast you can back up the data and how fast you can restore your data and how fast you can replicate the data to a remote site in case of a disaster. And it turns out that for many customers those other factors are important enough that they are willing to trade off some performance for read and write if they can get faster backups, restores and replication. And it further turns out that for many customers the performance of an operation is also a function of the ease to perform said operation. For example, if a restore takes 3 minutes to perform, but requires 8 hours to setup before you can hit the restore command, customer understand that the performance is really 8 hours and 3 minutes.
So really performance is a function of raw read and write, speed of backup, restore and replication and ease of use.
It turns out that if you optimize for any one of those vectors exclusively you will fail in the market place. To succeed you have to trade-off time and energy for one in favor of the other.
So where do the hard problems come from at NetApp?
So now I’ve hopefully explained where our hard problems comes from. In my next posts I’ll discuss each of these sub-bullets in more detail.